мНет описания правки Метки: Визуальный редактор apiedit |
Liebeann (обсуждение | вклад) Нет описания правки Метка: rte-source |
||
| Строка 1: | Строка 1: | ||
{{кластеризовать}} |
{{кластеризовать}} |
||
| + | == Функции потерь в задачах бинарной классификации == |
||
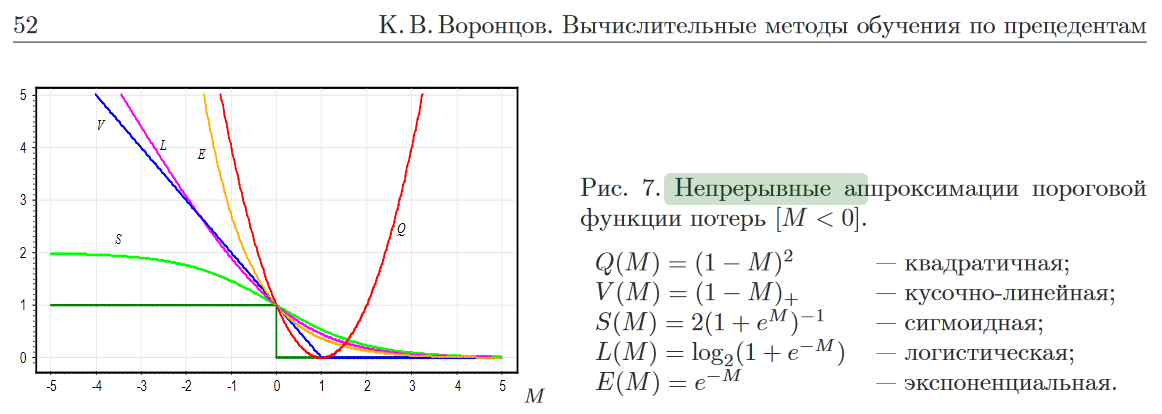
В задачах классификации наиболее естественным выбором является пороговая функция потерь <math>{\mathcal L}(y,y') = [y'\neq y].</math>Такая функция потерь разрывна, [[Метод минимизации эмпирического риска|минимизация эмпирического риска]] оказывается сложной задачей комбинаторной оптимизации. Поэтому используются всевозможные их непрерывные аппроксимации. |
В задачах классификации наиболее естественным выбором является пороговая функция потерь <math>{\mathcal L}(y,y') = [y'\neq y].</math>Такая функция потерь разрывна, [[Метод минимизации эмпирического риска|минимизация эмпирического риска]] оказывается сложной задачей комбинаторной оптимизации. Поэтому используются всевозможные их непрерывные аппроксимации. |
||
[[File:Непрерывные аппроксимации.png|thumb|691x691px]] |
[[File:Непрерывные аппроксимации.png|thumb|691x691px]] |
||
| Строка 8: | Строка 9: | ||
Основной недостаток — явление переобучения. |
Основной недостаток — явление переобучения. |
||
| + | == Функции потерь, порождающие оптимальные веса, зависящие от части выборки == |
||
| − | + | Такой является '''кусочно-линейная функция потерь''' (или '''hinge loss'''). Она просто зануляется на тех объектах, которые достаточно далеко от разделяющей поверхности. Задачу оптимизации в [[Метод опорных векторов (Support vector machine)|SVM]] можно также переписать, используя hinge loss. |
|
Источники: |
Источники: |
||
Версия от 19:32, 5 января 2017
 |
Эта статья нуждается в структуризации!
|
Функции потерь в задачах бинарной классификации
В задачах классификации наиболее естественным выбором является пороговая функция потерь Такая функция потерь разрывна, минимизация эмпирического риска оказывается сложной задачей комбинаторной оптимизации. Поэтому используются всевозможные их непрерывные аппроксимации.
![{\displaystyle {\mathcal {L}}(y,y')=[y'\neq y].}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/88b44ac4ee17e37d667d04ec4d0d0552eb37dbfa)
В задачах регрессии наиболее типичным выбором является квадратичная функция потерь

{kind=link}
{kind=link}
Основное достоинство метода: это конструктивный и универсальный подход, позволяющий сводить задачу обучения к задачам численной оптимизации.
Основной недостаток — явление переобучения.
Функции потерь, порождающие оптимальные веса, зависящие от части выборки
Такой является кусочно-линейная функция потерь (или hinge loss). Она просто зануляется на тех объектах, которые достаточно далеко от разделяющей поверхности. Задачу оптимизации в SVM можно также переписать, используя hinge loss.
Источники:
http://www.machinelearning.ru/wiki/images/6/68/voron-ML-Lin.pdf
https://en.wikipedia.org/wiki/Loss_functions_for_classification