Liebeann (обсуждение | вклад) (Новая страница: «== Bias-Variance decomposition для объекта == Пусть <math>y = f(x) + \varepsilon, \varepsilon \tilde \mathcal{N}(0, \sigma^2)</math> и произ…») Метка: rte-source |
Liebeann (обсуждение | вклад) Нет описания правки Метка: rte-source |
||
| Строка 1: | Строка 1: | ||
== Bias-Variance decomposition для объекта == |
== Bias-Variance decomposition для объекта == |
||
| − | Пусть <math>y = f(x) + \varepsilon, \varepsilon \ |
+ | Пусть <math>y = f(x) + \varepsilon, \varepsilon \sim \mathcal{N}(0, \sigma^2)</math> и производится обучение алгоритма <math>\hat f(\mathbb X)(x)</math> на некоторой выборке <math>\mathbb{X, Y}</math>. Тогда среднеквадратичный риск <math>R(\hat f) = \mathbb E_{\mathbb X, \mathbb Y} (\hat f(\mathbb X)(x) - y)^2</math> можно выразить, как: |
<math>R(\hat f) = \left(\mathbb E_{\mathbb X, \mathbb Y} \hat f (\mathbb X)(x) - f(x)\right)^2 + \mathbb E_{\mathbb X, \mathbb Y} \left(\hat f (\mathbb X)(x) - \mathbb E_{\mathbb X}\hat f (\mathbb X)(x) \right)^2 + \sigma ^2</math> |
<math>R(\hat f) = \left(\mathbb E_{\mathbb X, \mathbb Y} \hat f (\mathbb X)(x) - f(x)\right)^2 + \mathbb E_{\mathbb X, \mathbb Y} \left(\hat f (\mathbb X)(x) - \mathbb E_{\mathbb X}\hat f (\mathbb X)(x) \right)^2 + \sigma ^2</math> |
||
| + | |||
| + | * <math>\left(\mathbb E_{\mathbb X, \mathbb Y} \hat f (\mathbb X)(x) - f(x)\right)^2</math> --- квадрат смещения. |
||
| + | |||
| + | * <math>\mathbb E_{\mathbb X, \mathbb Y} \left(\hat f (\mathbb X)(x) - \mathbb E_{\mathbb X}\hat f (\mathbb X)(x) \right)^2</math> --- разброс. |
||
| + | |||
| + | * <math>\sigma^2</math> --- неустранимый шум. |
||
| + | |||
| + | Более короткая запись: |
||
| + | |||
| + | <math>\text{MSE} = \text{bias}^2 + \text{variance} + \text{noise}</math> |
||
| + | |||
| + | === Доказательство === |
||
| + | |||
| + | Подробно доказательство проводится [http://www.machinelearning.ru/wiki/images/9/95/Kitov-ML-eng-13-Ensemble_methods.pdf#page=24 тут] |
||
| + | |||
| + | == Bias-Variance decomposition c усреднением по всем объектам == |
||
| + | [[Файл:3.png|thumb|396px]] |
||
| + | |||
| + | |||
| + | Более подробно почитать про это можно [https://github.com/esokolov/ml-course-hse/blob/master/2016-fall/seminars/sem08-ensembles.pdf тут] |
||
Версия от 17:02, 23 июня 2017
Bias-Variance decomposition для объекта
Пусть и производится обучение алгоритма на некоторой выборке . Тогда среднеквадратичный риск можно выразить, как:





- --- квадрат смещения.

- --- разброс.

- --- неустранимый шум.

Более короткая запись:

Доказательство
Подробно доказательство проводится тут
Bias-Variance decomposition c усреднением по всем объектам
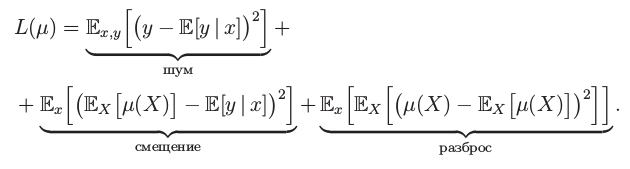
{kind=link}
Более подробно почитать про это можно тут