Liebeann (обсуждение | вклад) Нет описания правки Метка: rte-source |
Метка: Правка исходного кода |
||
| (не показано 8 промежуточных версий 1 участника) | |||
| Строка 9: | Строка 9: | ||
* Ответ ищется, как <math>\hat y(x) = \underset{c \in [1, \dots, C] }{\operatorname{argmax}} f_c(x)</math>. |
* Ответ ищется, как <math>\hat y(x) = \underset{c \in [1, \dots, C] }{\operatorname{argmax}} f_c(x)</math>. |
||
| − | == One-versus- |
+ | == One-versus-one подход == |
[[Файл:2.png|thumb|284px]] |
[[Файл:2.png|thumb|284px]] |
||
| − | * Обучим <math>\dfrac{C(C - 1)}{2}</math> |
+ | * Обучим <math>\dfrac{C(C - 1)}{2}</math> '''бинарных''' классификаторов следующим образом: для каждой пары <math>i, j \in [1, \dots, C], i \ne j</math> обучим бинарный классификатор <math>f_{i, j}(x)</math> на тех объектах тренировочной выборки, ответ которых принимает значение <math>i</math> или <math>j</math>. |
* В результате получим <math>\dfrac{C(C - 1)}{2}</math> классификаторов <math>f_{i, j}(x)</math>. |
* В результате получим <math>\dfrac{C(C - 1)}{2}</math> классификаторов <math>f_{i, j}(x)</math>. |
||
| + | * На этапе предсказания каждый из всех обученных классификаторов возвращает индикатор принадлежности соответствующему классу. Тот класс, за который проголосовало большинство и будет ответом на данном объекте: |
||
| ⚫ | |||
| + | |||
| ⚫ | |||
== Коды, исправляющие ошибки == |
== Коды, исправляющие ошибки == |
||
| − | * Каждый номер класса кодируется |
+ | * Каждый номер класса кодируется бинарным вектором <math>W_i</math>, состоящим из <math>B</math> бит, причем, <math>B \ge \lceil \log_2 C \rceil</math>. |
| − | * Строится B бинарных классификаторов f_b(x), которые предсказывают b-ый бит. |
+ | * Строится <math>B</math> бинарных классификаторов <math>f_b(x)</math>, которые предсказывают <math>b</math>-ый бит. |
| − | * Ответ ищется как <math>\hat y(x) = \underset{c \in [1, \dots, C] }{\operatorname{argmin}} \sum \limits_{b = 1}^B |W_{cb} - f_b(x)|</math>, где W_{cb} --- b-ый бит кодового слова для класса c. |
+ | * Ответ ищется как <math>\hat y(x) = \underset{c \in [1, \dots, C] }{\operatorname{argmin}} \sum \limits_{b = 1}^B |W_{cb} - f_b(x)|</math>, где <math>W_{cb}</math> --- <math>b</math>-ый бит кодового слова для класса <math>c</math>. |
* Чем больше бит используется при кодировании классов, тем более модель устойчива к ошибкам классификаторов. |
* Чем больше бит используется при кодировании классов, тем более модель устойчива к ошибкам классификаторов. |
||
* Кодирование производится рандомно или так, чтобы попарные расстояния Хэмминга между кодами были как можно больше. |
* Кодирование производится рандомно или так, чтобы попарные расстояния Хэмминга между кодами были как можно больше. |
||
| + | |||
| + | Ещё по этой теме [[Классификация с кодированием целевой переменной|здесь]]. |
||
== Ссылки == |
== Ссылки == |
||
| − | [http://www.machinelearning.ru/wiki/images/4/4e/Kitov-ML-eng-07-Linear_methods_of_classification.pdf#page=10 |
+ | [http://www.machinelearning.ru/wiki/images/4/4e/Kitov-ML-eng-07-Linear_methods_of_classification.pdf#page=10 слайды Китова] |
| − | [http://www.machinelearning.ru/wiki/images/9/95/Kitov-ML-eng-13-Ensemble_methods.pdf#page= |
+ | [http://www.machinelearning.ru/wiki/images/9/95/Kitov-ML-eng-13-Ensemble_methods.pdf#page=5 слайды Китова] |
Текущая версия от 13:39, 10 января 2021
Пусть рассматривается задача классификации с классами.

One-versus-all подход[]
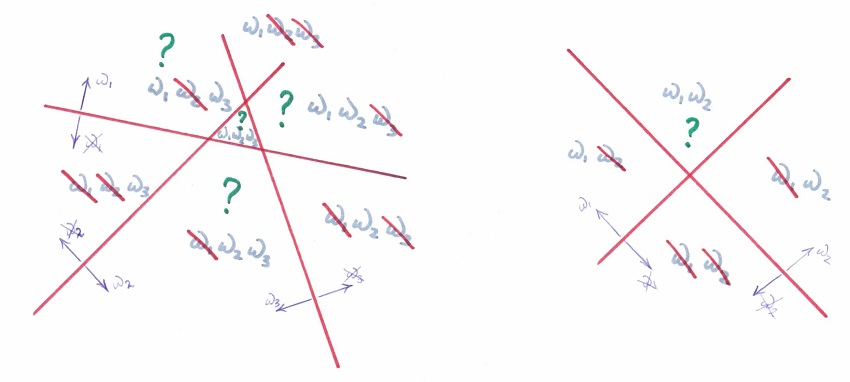
- Обучим на всех объектах тренировочной выборки бинарных классификаторов типа "принадлежит ли объект -ому классу".
- В результате получим классификаторов .
- Ответ ищется, как .


![{\displaystyle {\hat {y}}(x)={\underset {c\in [1,\dots ,C]}{\operatorname {argmax} }}f_{c}(x)}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/b99f0eef15caa977153fb63ddfc5a1b3d7c494bc)
One-versus-one подход[]

- Обучим бинарных классификаторов следующим образом: для каждой пары обучим бинарный классификатор на тех объектах тренировочной выборки, ответ которых принимает значение или .
- В результате получим классификаторов .
- На этапе предсказания каждый из всех обученных классификаторов возвращает индикатор принадлежности соответствующему классу. Тот класс, за который проголосовало большинство и будет ответом на данном объекте:

![{\displaystyle i,j\in [1,\dots ,C],i\neq j}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/1460c2ac2736d2e14c463e6e4af4c7b2a83cccfb)


.
![{\displaystyle {\hat {y}}(x)={\underset {c\in [1,\dots ,C]}{\operatorname {argmax} }}\sum \limits _{i\neq j\in [1,\dots ,C]}\mathbb {I} [f_{i,j}(x)==c]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/8e60c480fad2f84cc552e530ceb71c79807af1be)
Коды, исправляющие ошибки[]
- Каждый номер класса кодируется бинарным вектором , состоящим из бит, причем, .
- Строится бинарных классификаторов , которые предсказывают -ый бит.
- Ответ ищется как , где --- -ый бит кодового слова для класса .
- Чем больше бит используется при кодировании классов, тем более модель устойчива к ошибкам классификаторов.
- Кодирование производится рандомно или так, чтобы попарные расстояния Хэмминга между кодами были как можно больше.





![{\displaystyle {\hat {y}}(x)={\underset {c\in [1,\dots ,C]}{\operatorname {argmin} }}\sum \limits _{b=1}^{B}|W_{cb}-f_{b}(x)|}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/a2f2fa90d0db5d579c50517edc8db90de6215867)


{kind=link}
{kind=link}
Ещё по этой теме здесь.