Liebeann (обсуждение | вклад) (Новая страница: «== Ансамблирование моделей == Файл:5.png '''Идея:''' обучаем несколько базовых моделей, а за…») Метка: rte-source |
мНет описания правки Метка: Визуальный редактор |
||
| (не показано 9 промежуточных версий 1 участника) | |||
| Строка 1: | Строка 1: | ||
| + | {{Викифицировать}} |
||
| + | |||
== Ансамблирование моделей == |
== Ансамблирование моделей == |
||
[[Файл:5.png]] |
[[Файл:5.png]] |
||
| + | === Идея алгоритма === |
||
| ⚫ | |||
| + | |||
| − | ''' |
||
| ⚫ | |||
| ⚫ | |||
| + | |||
| ⚫ | |||
* В совокупности получаем более сложную модель, чем каждая в отдельности |
* В совокупности получаем более сложную модель, чем каждая в отдельности |
||
| Строка 12: | Строка 16: | ||
* Возможность работы с признаками разной природы (использовать разные алгоритмы) |
* Возможность работы с признаками разной природы (использовать разные алгоритмы) |
||
| − | Для простоты рассмотрим задачу бинарной классификации. Пусть всего N базовых моделей и каждая предсказывает класс c_1 или c_2. Тогда агрегированный алгоритм может выдавать класс c_1 по следующим правилам: |
+ | Для простоты рассмотрим задачу бинарной классификации. Пусть всего <math>N</math> базовых моделей и каждая предсказывает класс <math>c_1</math> или <math>c_2</math>. Тогда агрегированный алгоритм может выдавать класс <math>c_1</math> по следующим правилам: |
| + | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| + | |||
| + | Почему ансамблирование улучшает результат описано [[Ансамблирование простым голосованием: предельный случай|здесь]]. |
||
| + | |||
| + | === Обобщение с весами === |
||
| + | |||
| + | Также, если используются правила <math>k</math>-out-of-<math>N</math> или majority vote, можно каждой базовой модели присвоить вес, основываясь на качестве предсказания на валидационной выборке. |
||
| + | |||
| + | === Предсказание класса по уровням ранжирования === |
||
| + | |||
| + | Пусть теперь рассматривается задачи многоклассовой классификации с <math>C</math> классами. Пусть каждая <math>k</math>-ая базовая модель выдает некую отранжированную информацию о классе объекта: |
||
| + | |||
| + | <math>c_{k_1} \succcurlyeq c_{k_2} \succcurlyeq \dots \succcurlyeq c_{k_C}</math> |
||
| + | |||
| + | Это означает, что класс <math>c_{k_1}</math> наиболее вероятен для рассматриваемого объекта, а класс <math>c_{k_C}</math> --- наименее вероятен. |
||
| + | |||
| + | Пусть <math>B_k(i)</math> --- сколько классов было отранжировано ниже <math>i</math>-го класса <math>k</math>-ой базовой моделью. Чем <math>B_k(i)</math> выше, тем более вероятен <math>i</math>-ый класс. Поэтому, в качестве совокупного рейтинга построим следующую величину: |
||
| + | |||
| + | <math>g_i(x) = \sum \limits_{k} B_k(i, x)</math> |
||
| + | |||
| + | Тогда результирующее предсказание на объекте <math>x</math>: |
||
| + | |||
| + | <math>\hat y(x) = \underset{i \in [1, \dots, C] }{\operatorname{argmax}}~~g_i(x)</math> |
||
| + | |||
| + | === Предсказание класса по вероятностям === |
||
| + | |||
| + | Опять рассмотрим задачу многоклассовой классификации с <math>C</math> классами. Пусть каждая <math>k</math>-ая базовая модель выдает вектор вероятностей из принадлежностей к каждому классу: |
||
| + | |||
| + | <math>[p^k(c_1), p^k(c_2), \dots, p^k(c_C)]</math> |
||
| + | |||
| + | Тогда <math>\hat y(x) = c_i</math>, где <math>i = \underset{i \in [1, \dots, C] }{\operatorname{argmax}}~~F(p^1(c_i), p^2(c_i), \dots, p^N(c_i))</math> |
||
| + | |||
| + | <math>F</math> --- среднее арифметическое или медиана. |
||
| + | |||
| + | == Стэкинг моделей == |
||
| + | |||
| + | Рассмотрим задачу регрессии. Пусть всего <math>K</math> базовых моделей каждая модель --- это <math>f_k(x)</math> алгоритмов регрессии. Результирующую модель строим следующим образом: |
||
| + | |||
| + | <math>f(x) = \sum \limits_{k = 1}^K w_k f_k(x)</math> |
||
| + | |||
| + | Можно находить веса следующим образом: |
||
| + | |||
| + | <math>\hat w = \underset{w}{\operatorname{argmin}}~\sum \limits_{i=1}^N \mathcal L(y_i, \sum \limits_{k = 1}^K w_k f_k(x_i))</math> |
||
| + | |||
| + | Но такой способ приведет к переобучению. Поэтому будем находить веса при помощи кросс-валидации, а именно: разобьем выборке на <math>M</math> частей. Пусть <math>fold(i)</math> --- та часть, которая содержит <math>i</math>-ый объект, а <math>f_k^{-fold(i)}</math> --- алгоритм, обученный на всех фолдах, кроме <math>fold(i)</math>. Тогда: |
||
| + | |||
| + | <math>\hat w = \underset{w}{\operatorname{argmin}}~\sum \limits_{i=1}^N \mathcal L(y_i, \sum \limits_{k = 1}^K w_k f_k^{-fold(i)}(x_i))</math> |
||
| + | |||
| + | Для уменьшения переобучения можно добавить условия на неотрицательность весов или добавить к функционалу регуляризатор <math>\lambda \sum \limits_{k=1}^K(w_k - \dfrac{1}{K})^2</math> |
||
| + | |||
| + | == Обобщенный стэкинг == |
||
| + | |||
| + | Предполагаем, что |
||
| + | |||
| + | <math>f(x) = A_{\theta}(f_1(x), \dots, f_K(x))</math> |
||
| + | |||
| + | ,где <math>\theta</math> --- вектор параметров: |
||
| + | |||
| + | <math>\hat \theta = \underset{\theta}{\operatorname{argmin}}~\sum \limits_{i=1}^N \mathcal L(y_i, A_{\theta}(f_1^{-fold(i)}(x), \dots, f_K^{-fold(i)}(x)))</math> |
||
| + | |||
| + | <math>f_i(x)</math>: |
||
| + | * Номер класса |
||
| + | * Вектор вероятностей классов |
||
| + | * Любой изначальный или сгенерированный признак |
||
| + | |||
| + | == Бэггинг (Bagging) == |
||
| + | |||
| + | Генерируем <math>K</math> выборок фиксированного размера <math>M</math>, выбирая с возвращением из <math>N</math> имеющихся объектов. Доказывается, что каждый объект попадает в выборку с вероятностью <math>1 - e^{-1}</math>, если <math>M = N</math>. |
||
| + | |||
| + | Настраиваем <math>K</math> базовых моделей на этих выборках и агрегируем результат. |
||
| + | |||
| + | '''Плюсы:''' |
||
| + | * Уменьшает переобучение, если базовые модели были переобучены (например, решающие деревья) |
||
| + | |||
| + | '''Минусы:''' |
||
| + | * Время обучения увеличивается в <math>K</math> раз |
||
| + | |||
| + | == Метод случайных подпространств (Random subspace method) == |
||
| + | |||
| + | Разбиваем без возвращения признаки случайных образом (причем, не обязательно, чтобы было одинаковое количество признаков) |
||
| + | |||
| + | * Можно объединять два вышеприведенных подхода, то есть, фактически, выбирать подматрицы матрицы <math>\mathbb X</math>. |
||
| + | |||
| + | == Случайный лес (Random Forest) == |
||
| + | |||
| + | ''Базовые алгоритмы'' --- решающие деревья. Пусть всего <math>B</math> базовых алгоритмов и размер подвыборки признаков --- <math>m</math>. Тогда, алгоритм построения случайного леса следующий: |
||
| + | |||
| + | * Генерируем при помощи бэггинга <math>B</math> выборок |
||
| + | * Обучаем каждое решающее дерево на своей выборке, причем в '''каждом узле признаки рассматриваются из случайно выбранного подмножества размера <math>m</math> из всех признаков.''' |
||
| + | |||
| + | Агрегирование результата в случае классификации производится при помощи голосования большинства, а в случае регрессии --- среднее арифметическое. |
||
| + | |||
| + | '''Плюсы:''' |
||
| + | * Можно осуществить параллельную реализацию |
||
| + | * Не переобучается с ростом <math>B</math> |
||
| + | |||
| + | '''Минусы:''' |
||
| + | * Менее интерпретируемый, чем решающее дерево |
||
| + | * Деревья не исправляют ошибки друг друга |
||
| + | |||
| + | Для обучения должны использоваться глубокие деревья, иначе бэггинг над простыми моделями даст простую модель. |
||
| + | |||
| + | == Extra Random Trees == |
||
| + | |||
| + | В каждом узле дерева генерируется случайно <math>m</math> пар (признак, порог). |
||
| + | |||
| + | '''Плюсы:''' |
||
| + | * Упрощение модели Random Forest |
||
| + | * Более быстрые, чем Random Forest |
||
| + | * Не переобучается с ростом <math>B</math> |
||
| + | |||
| + | '''Минусы:''' |
||
| + | * Bias выше, чем у Random Forest, а variance --- меньше. |
||
| + | |||
| + | Для обучения должны использоваться глубокие деревья |
||
| + | |||
| + | == Ссылки == |
||
| + | |||
| + | [http://www.machinelearning.ru/wiki/images/4/4e/Kitov-ML-eng-07-Linear_methods_of_classification.pdf слайды Китова] |
||
| + | |||
| + | [https://github.com/esokolov/ml-course-hse/blob/master/2016-fall/seminars/sem08-ensembles.pdf семинары Соколова по бэггингу] |
||
| + | [https://github.com/esokolov/ml-course-hse/blob/master/2016-fall/lecture-notes/lecture08-ensembles.pdf семинары Соколова по Random Forest] |
||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
Текущая версия от 15:39, 25 декабря 2017
 |
Эта статья плохо повышает индекс цитируемости авторов других статей этой вики.
|
Ансамблирование моделей[]
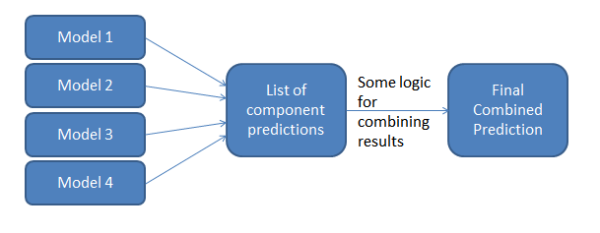
Идея алгоритма[]
Обучаем несколько базовых моделей, а затем агрегируем их результаты по какому-либо правилу и выдаем окончательный результат.
Зачем это нужно:
- В совокупности получаем более сложную модель, чем каждая в отдельности
- Уменьшение разбора
- Избежание переобучения/недообучения
- Возможность работы с признаками разной природы (использовать разные алгоритмы)
Для простоты рассмотрим задачу бинарной классификации. Пусть всего базовых моделей и каждая предсказывает класс или . Тогда агрегированный алгоритм может выдавать класс по следующим правилам:



- AND-правило: если все базовые модели выдали
- OR-правило: если хотя бы одна базовая модель выдала
- -out-of-: если хотя бы базовых моделей из выдали
- majority vote: если большинство базовых моделей выдало

Почему ансамблирование улучшает результат описано здесь.
Обобщение с весами[]
Также, если используются правила -out-of- или majority vote, можно каждой базовой модели присвоить вес, основываясь на качестве предсказания на валидационной выборке.
Предсказание класса по уровням ранжирования[]
Пусть теперь рассматривается задачи многоклассовой классификации с классами. Пусть каждая -ая базовая модель выдает некую отранжированную информацию о классе объекта:


Это означает, что класс наиболее вероятен для рассматриваемого объекта, а класс --- наименее вероятен.


Пусть --- сколько классов было отранжировано ниже -го класса -ой базовой моделью. Чем выше, тем более вероятен -ый класс. Поэтому, в качестве совокупного рейтинга построим следующую величину:



Тогда результирующее предсказание на объекте :

![{\displaystyle {\hat {y}}(x)={\underset {i\in [1,\dots ,C]}{\operatorname {argmax} }}~~g_{i}(x)}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/4ebe5ff59ef138db9dad21d159c57090c0190293)
Предсказание класса по вероятностям[]
Опять рассмотрим задачу многоклассовой классификации с классами. Пусть каждая -ая базовая модель выдает вектор вероятностей из принадлежностей к каждому классу:
![{\displaystyle [p^{k}(c_{1}),p^{k}(c_{2}),\dots ,p^{k}(c_{C})]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/5bca6b8a8479935288cd9f948ee1f9bc24e34367)
Тогда , где

![{\displaystyle i={\underset {i\in [1,\dots ,C]}{\operatorname {argmax} }}~~F(p^{1}(c_{i}),p^{2}(c_{i}),\dots ,p^{N}(c_{i}))}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/3f06e9ba64c92915a712c3a357975becb4c3138a)
--- среднее арифметическое или медиана.

Стэкинг моделей[]
Рассмотрим задачу регрессии. Пусть всего базовых моделей каждая модель --- это алгоритмов регрессии. Результирующую модель строим следующим образом:



Можно находить веса следующим образом:

Но такой способ приведет к переобучению. Поэтому будем находить веса при помощи кросс-валидации, а именно: разобьем выборке на частей. Пусть --- та часть, которая содержит -ый объект, а --- алгоритм, обученный на всех фолдах, кроме . Тогда:




Для уменьшения переобучения можно добавить условия на неотрицательность весов или добавить к функционалу регуляризатор

Обобщенный стэкинг[]
Предполагаем, что

,где --- вектор параметров:


:

- Номер класса
- Вектор вероятностей классов
- Любой изначальный или сгенерированный признак
Бэггинг (Bagging)[]
Генерируем выборок фиксированного размера , выбирая с возвращением из имеющихся объектов. Доказывается, что каждый объект попадает в выборку с вероятностью , если .


Настраиваем базовых моделей на этих выборках и агрегируем результат.
Плюсы:
- Уменьшает переобучение, если базовые модели были переобучены (например, решающие деревья)
Минусы:
- Время обучения увеличивается в раз
Метод случайных подпространств (Random subspace method)[]
Разбиваем без возвращения признаки случайных образом (причем, не обязательно, чтобы было одинаковое количество признаков)
- Можно объединять два вышеприведенных подхода, то есть, фактически, выбирать подматрицы матрицы .

Случайный лес (Random Forest)[]
Базовые алгоритмы --- решающие деревья. Пусть всего базовых алгоритмов и размер подвыборки признаков --- . Тогда, алгоритм построения случайного леса следующий:


{kind=link}
{kind=link}
- Генерируем при помощи бэггинга выборок
- Обучаем каждое решающее дерево на своей выборке, причем в каждом узле признаки рассматриваются из случайно выбранного подмножества размера из всех признаков.
Агрегирование результата в случае классификации производится при помощи голосования большинства, а в случае регрессии --- среднее арифметическое.
Плюсы:
- Можно осуществить параллельную реализацию
- Не переобучается с ростом
Минусы:
- Менее интерпретируемый, чем решающее дерево
- Деревья не исправляют ошибки друг друга
Для обучения должны использоваться глубокие деревья, иначе бэггинг над простыми моделями даст простую модель.
Extra Random Trees[]
В каждом узле дерева генерируется случайно пар (признак, порог).
Плюсы:
- Упрощение модели Random Forest
- Более быстрые, чем Random Forest
- Не переобучается с ростом
Минусы:
- Bias выше, чем у Random Forest, а variance --- меньше.
Для обучения должны использоваться глубокие деревья